如果说知识是人类进步的阶梯,那么知识图谱就好比是AI进步的阶梯。
从2018年起就开始参与一个知识图谱的项目,由于知识图谱还是一个比较前沿的方向,当时我们的整个团队也是摸着石头过河,从对知识图谱一窍不通,到现在有一些自己的理解,所以想写一个知识图谱的专题系列,既可以对以前看过的东西加深印象,另一方面也是梳理一下这一块儿的一个知识脉络。
本文主要是开个头,对知识图谱进行一个概述,主要分为一下几个部分:
- 什么是知识图谱;
- 知识图谱的发展历程;
- 知识图谱的关键技术;
- 知识图谱的典型应用场景,及发展方向;
- 参考资料;
当然很多问题仅限于我自己的思考,不一定全面,甚至存在一些以偏概全或者理解不正确的地方,欢迎指正一起讨论。
什么是知识图谱?
知识图谱的概念最开始来源于Google知识图谱,2012年Google基于语义网、link data发布了谷歌知识图谱,也就是Google知识库,用于提高Google搜索的质量,自此知识图谱就不断吸引相关学者以及科研机构的关注。
针对通俗的知识图谱的定义,不同的资料有不同的解释,我个人觉得东南大学的漆桂林教授的定义还是比较准确的(漆老师是东南大学计算机系的教授,对知识图谱有很深入的研究):
知识图谱是人工智能中研究如何将人类的知识转化为图,从而方便计算机存储并用于推理,计算机可以通过知识图谱实现从感知智能到认知智能的飞跃,支持智能问答、辅助决策、智能分析等应用。
翻译一下就是说,知识图谱是通过图结构的方式将人类的知识进行积累存储,这种结构便于知识的存储与推理,而知识推理正是认知智能的一个核心能力。
知识图谱是由一个一个(实体-关系-实体)这样的三元组构成的图结构,实体是客观世界中的事物,关系则表示不同事物之间的关联关系,实体和关系可以有各自的属性。
下图所示的例子,就是由几个三元组构成的一个简单的知识图谱结构:
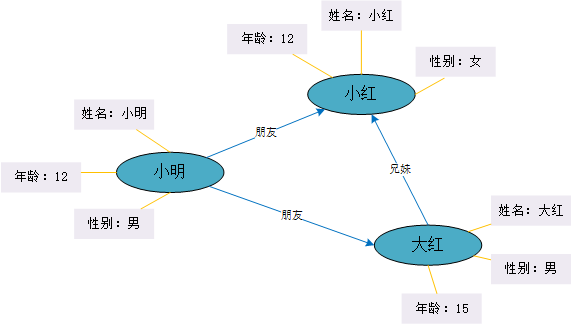
在这张图中,通过三元组的方式定义了三个实体:小明,小红,大红,以及他们各自的属性,包括姓名,性别,年龄等信息,通过关系将一个一个的实体关联起来。
更复杂的知识图谱如下所示,有更多的三元组构成,包含的知识信息也更加丰富:
知识图谱的发展历程
专家系统
其实,知识图谱技术的前身可以一直追溯到上世纪70年代的“专家系统”,通过将特定领域的知识与经验集成到智能程序系统,通过知识库加规则推理机的方式实现智能专家系统,来解决一些特定领域的问题,在当时取得了不小的成功,当时比较知名的专家系统有MYCIN医疗诊断专家系统、识别分子结构的DENRAL专家系统,计算机故障针对XCON专家系统等,但是缺点是需要过多的人工干预。
Web3.0
如何高效的获取知识?为了克服人肉填充知识的挑战,万维网之父Berners-Lee最初在设计互联网的初衷就是通过网络把全世界的知识互联在一起,使得知识从封闭走向开放。
首先应该构造一个文档互联的网络,然后在这个基础上再构建一个可以让计算机识别的知识互联的网络。
第一个目标——文档互联,已经实现了,也就是我们现在的互联网,那么第二个目标——知识互联呢?
在web2.0中,互联网上的数据大多以html网页的形式存在,很方便人机交互,但是要让计算机理解各个网页的内容以及相互之间的关联,缺乏明确的语义表示,面对信息时代的海量信息,让计算机自动获取知识面临着不小的挑战。
1998年,Berners-Lee提出“语义网”(Semantic Web)的概念,也就是后来常说的web3.0。语义网的目标是对现有的web内容增加语义支持,从而让计算机可以自动识别和理解互联网上的信息,以及相互之间的关联。为了实现语义网络,提出了很多语义网相关的标准与规范,主要包括RDF(资源描述框架)、RDFS(带Schema的RDF)、OWL等规范。
RDF提供了一个统一的标准,用于描述实体/资源,RDF规定通过SPO(即Subject,Predicate,Object,也即主谓宾)三元组来描述事物。

通过这种SPO三元组来表示存在于互联网世界中的各种资源,这样当计算机读取到RDF文件,就可以根据RDF标准来解析出各个事物(资源)的信息,但是RDF的表达能力比较弱,缺乏抽象能力,无法对同一类别的资源进行定义和描述,而且很难表示出各个资源之间的关系。
于是后来提出了RDFS和OWL标准,二者都是用来描述RDF数据的,目的是提高对资源的抽象能力以及表达能力,学过面向对象编程的都理解,类是对一类事物的抽象,对象则是某个具体事物的实例化,比如Person是一个类,Person xiaoming是该类的一个具体实例,RDF可以理解是对一个一个的具体的实例的描述,引入RDFS和OWL是为了更好的定义抽象类以及类与类之间的关系。
在web3.0时代,基于RDF,OWL等框架进行了大量的语义网络方面的工作,但是实现这个目标是一个相当艰巨的任务——需要把互联网上的海量信息通过这种语义框架进行表示。
随着大规模百科类半结构化知识资源的出现,以及一些自动知识提取算法的研究,对于自动地从互联网获取知识取得了相当大的进展,比如DBPedia,FreeBase等开放知识图谱都是基取得了瞩目的成果。
语义网到知识图谱
web3.0时代其实就是想通过RDF资源描述框架实现语义网,那么语义网跟当前所说的知识图谱技术有什么差别吗?
通过上面web3.0中的描述,语义网其实就是由RDF三元组构成的图结构,如果知识图谱是通过RDF技术栈实现的,则其和语义网等价,比如开源知识图谱FreeBase、规则推理机Jena、Drools、等都是基于RDF实现的。
但是知识图谱除了可以通过RDF三元组的形式构成图结构之外,也可以通过属性图的模式构成图结构,属性图用实体表示节点,用关系表示边,属性图中的所有值属性都可以存储在节点和边的对象,而RDF的数据属性需要显示地以节点和边的形式进行定义,通过属性图模式构建图结构的代表有图数据库:ArangoDB,Neo4j等。
当前有一种趋势是说:学术界使用RDF模型偏多,而工业界则使用属性图模型偏多。这主要是由于二者的优缺点决定的:
RDF模型:
优点:
1). 有一套严谨的定义框架;
2). 框架内置的关系约束(subclass of, disjoint with等)使得RDF模型天然支持规则推理;
缺点:
1). 严谨也就意味着不灵活,定义一套RDF模型的图结构,需要学习并不简单的RDF技术栈;
2). 虽然天然支持规则推理,但是需要将数据加载到内存进行推理,所以不适合大数据量的处理;属性图模型:
优点:
1). 定义起来很灵活,很符合人类的阅读理解习惯;
2). 有一些专门的图数据库,适合处理大数据量的场景;
缺点:
1). 需要实现额外的逻辑来进行知识推理;
知识图谱的关键技术
知识图谱主要分为开放知识图谱(也称为通用知识图谱)和行业知识图谱(也称为垂直领域知识图谱),开放知识图谱即表示面向开放领域的知识图谱,比如百度知识图谱等;而行业知识图谱即表示面向特定领域的知识图谱,比如医疗知识图谱、金融反诈骗知识图谱等。
无论是开放知识图谱还是行业知识图谱,主要的关键技术主要包括以下几个方面:
一. 知识表示和知识建模
要构建知识图谱,首先要进行知识表示,只有对原始的预料进行特定的知识表示,计算机才能读懂这些预料形成知识。
简单而言,知识表示(KR)就是用更易于计算机处理的方式来描述人脑的知识。
AI长河中出现了很多的知识表示方法:
- 一阶谓词逻辑(First-Order Logic)
- 产生式规则(Production Rule)
- 框架(Framework)
- 语义网络(Semantic Network)
- 逻辑程序(Logic Programming)
- 缺省逻辑(Default Logic)
- 模态逻辑(Modal Logic)
那知识建模即建立知识图谱的数据模式,对整个知识图谱的结构进行定义,常用的知识建模方法有:自顶向下的方法和自底向上的方法。
二. 知识抽取
知识抽取在知识图谱中主要解决的是知识来源的问题,即从不同来源、不同结构的语料数据中抽取出知识,存储到知识图谱。
根据原始预料数据类型的不同,知识抽取任务一般分为如下三类:
1. 结构化语料的知识抽取
2. 半结构化语料的知识抽取
3. 非结构化语料的抽取
涉及到的一些常用方法,如下图所示: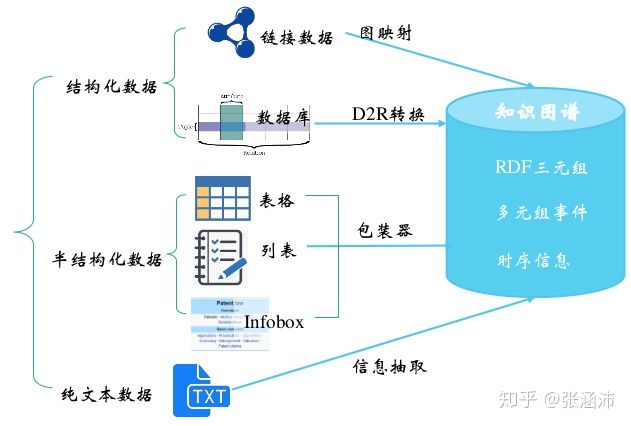
又根据抽取的目标不同,将知识抽取分为一下几个子任务:
1. 命名实体识别(NER)
命名实体检测:南京明天会下雨——[南京](实体)
命名实体分类:南京明天会下雨——[南京](地名)
2. 关键术语抽取
抽取关键概念或术语
3. 关系抽取
姚明是中国篮协的主席——[姚明]<是主席>[中国篮协]
4. 事件抽取
从原始预料中抽取出一件事件发生的相关信息,如时间、地点、人物等
三. 知识融合
维基百科认为知识融合是对来自多源的不同概念、上下文和不同表达等信息进行融合的过程;Smirnov 等人认为知识融合的目标是产生新的知识,是对松耦合来源中的知识进行集成,构成一个合成的资源, 用来补充不完全的知识和获取新知识;唐晓波等人在总结众多知识融合概念的基础上认为知识融合是知识组织与信息融合的交叉学科,它面向需求和创新,通过对众多分散、异构资源上知识的获取、匹配、集成、挖掘等处理,获取隐含的或有价值的新知识,同时优化知识的结构和内涵,提供知识服务。
知识融合主要分为数据层的知识融合和概念层的知识融合等。
数据层的知识融合
实体链接又称实体对齐问题是数据层知识融合研究的主要任务,其核心是构建多类型多模态上下文及知识的统一表示,并建模不同信息、不同证据之间的相互交互。
主要的实体链接技术有:基于实体知识的链接方法、基于篇章主题的链接方法以及二者相结合的实体链接方法。
概念层的知识融合
概念层的知识融合是对多个知识库或者信息源在概念层进行模式对齐的过程。本体对齐或者本体匹配是概念层知识融合的主要研究任务,是指确定本体概念间映射关系的过程。
本体匹配的研究核心在于如何通过本体概念之间的相似性度量,发现异构本体检的匹配关系,本体匹配基本方法主要包括:基于结构的方法、基于实例的方法、基于语言学的匹配算法、基于文本的匹配算法和基于已知实体连接的匹配算法。
四. 知识存储
经过知识表示、知识抽取、知识融合之后,需要对知识进行存储管理,那么知识存储就是解决这个问题的。
知识存储的内容包括本体库的存储、实例数据的存储、关系的存储等。
由于知识图谱天然的图结构模式,所以一般使用图数据库来进行知识存储。
图数据库是基于图理论的新型NoSQL(非关系型)数据库,图数据库以“图”的数据结构来存储和查询数据,相对传统的关系型数据库,查询速度快、操作简单、能提供丰富的关系展现方式。
当前比较主流的图数据库有Neo4j、ArangoDB等。
五. 知识推理
知识推理可定义为按照某种策略,根据现有知识推出新知识的过程。知识推理可以分为基于符号推理和基于统计的推理。在知识理解的基础上构建应用,知识图谱的应用大多基于对复杂网络的大规模计算,计算的结果,或以在线服务,或以离线结果的形式提供给应用侧。 基于知识推理的典型应用主要包括智能搜索、智能推荐、智能问答等。
六. 知识应用
知识图谱由于其中蕴含的丰富的语义信息,常备用于智能问答、知识推理、辅助决策分析等场景。
知识图谱的典型应用场景,及发展方向
参考资料
[1] 领域综述 | 知识图谱概论(一)
[2] 为什么需要知识图谱?什么是知识图谱?——KG的前世今生
[3] 知识图谱的表示与关系建模.浙江大学知识图谱导论课程课件.陈华钧